Observability outcomes that matter in practice
Search, metrics, alerts, and long retention in one tool at a fraction of the cost
01. Incident Investigation
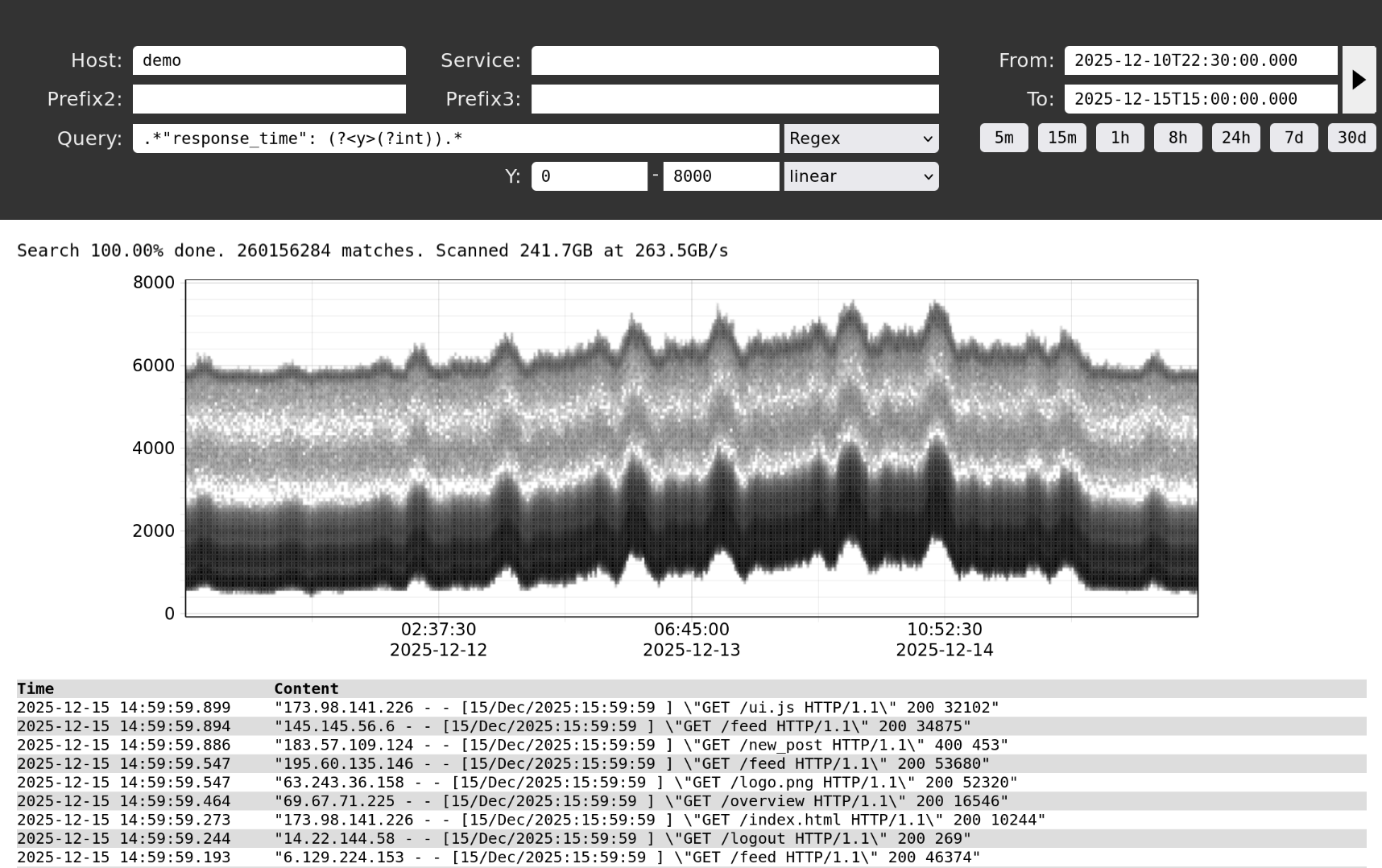
Find incidents fast from raw events
Good observability starts with being able to answer operational questions quickly. logging24 keeps full log detail searchable with fast regex-based queries, so teams can investigate incidents without waiting for re-indexing, field modeling, or preplanned dashboards.
02. Late-Bound Metrics
Create metrics after the fact
Many observability stacks force teams to decide in advance which fields deserve metric pipelines. logging24 takes the opposite approach: keep the raw events, then extract numeric values when the need appears. That makes new metrics possible during an incident, not only before one.
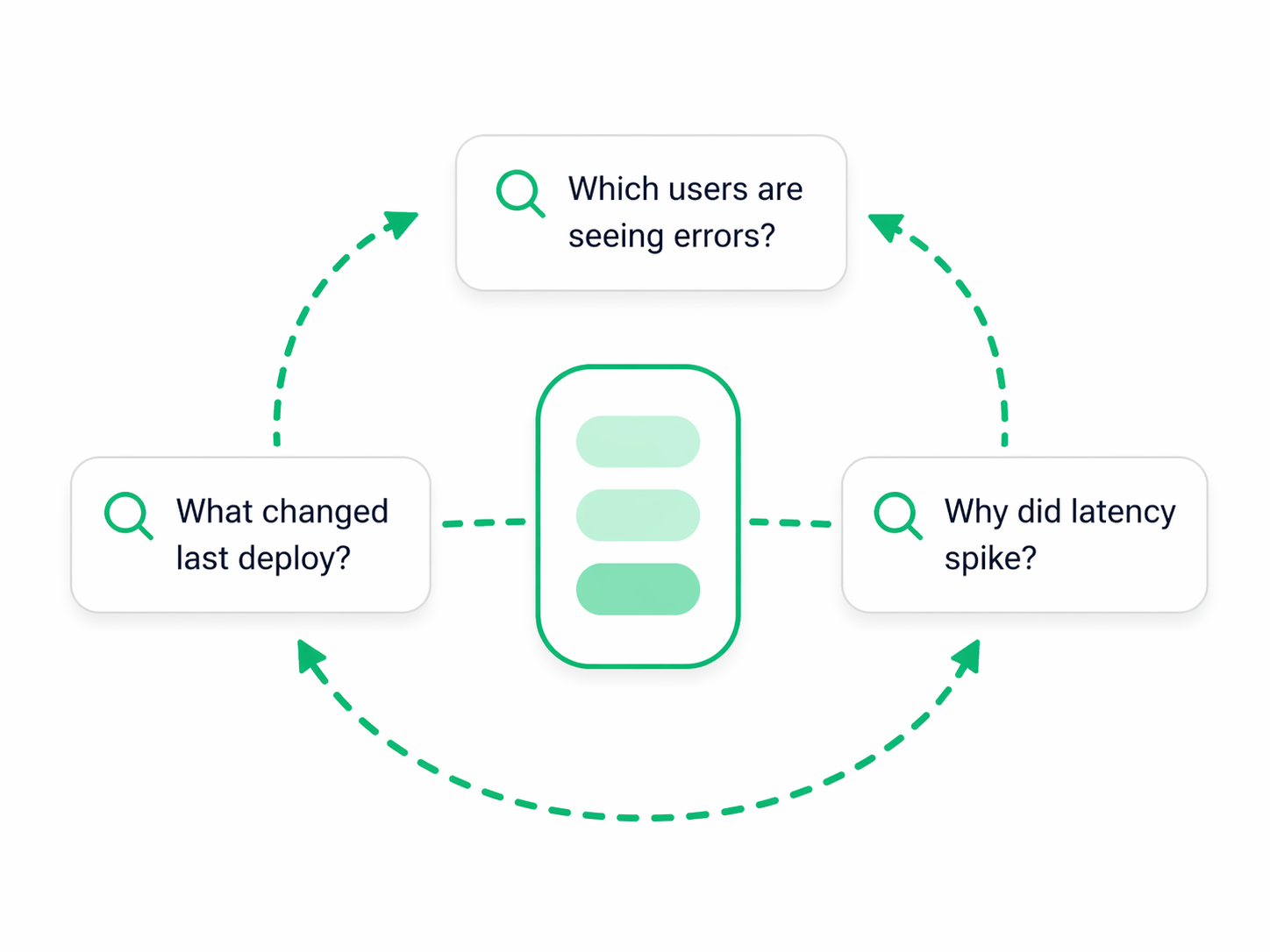
03. New Questions
Ask new questions on existing data
Observability is most valuable when the unknown question arrives. With one retained dataset, teams can come back later with new search patterns, grouping keys, and derived metrics instead of rebuilding collection rules or reprocessing old data.
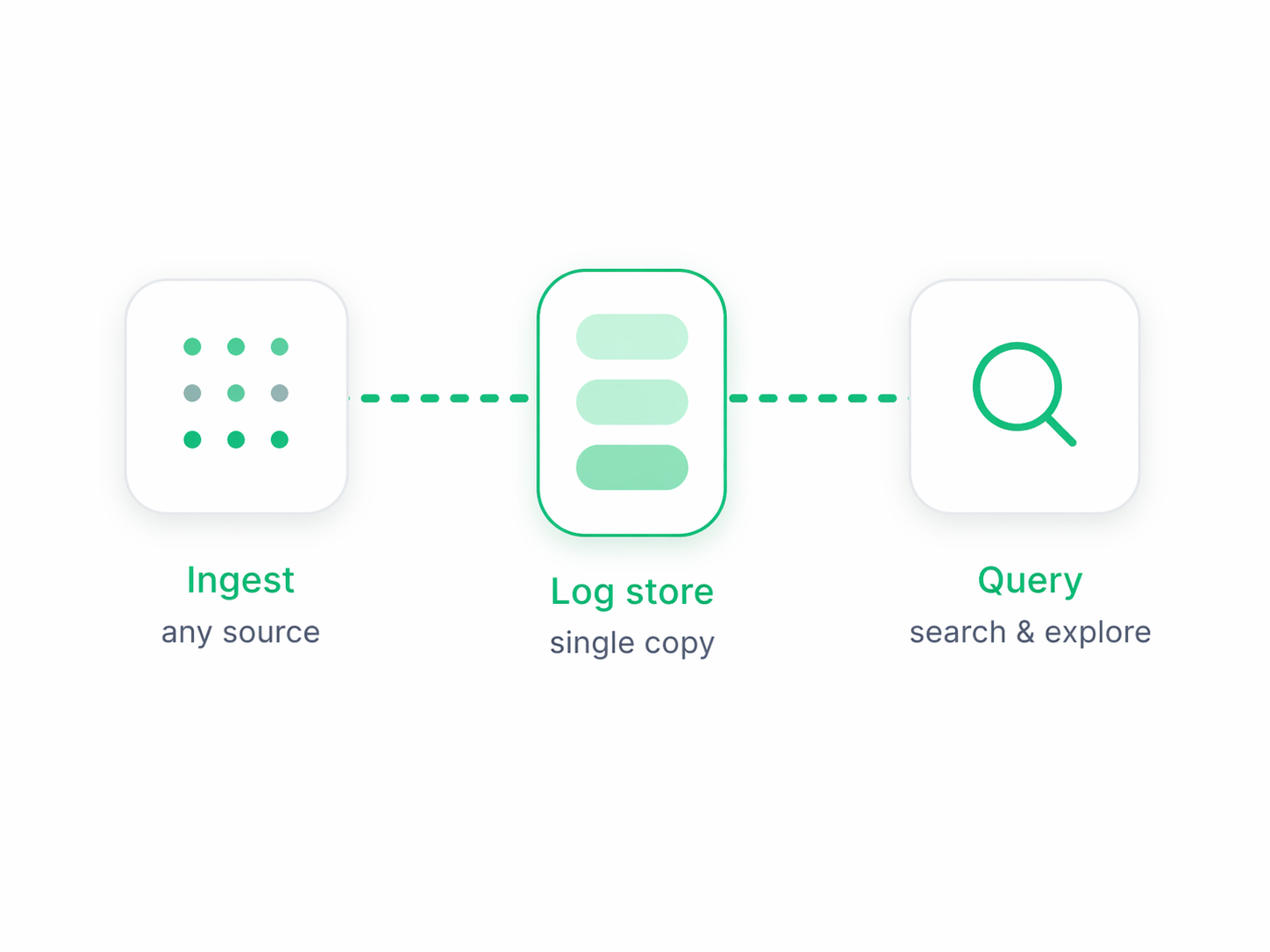
04. Operational Simplicity
Start quickly and scale cleanly
Observability architecture should get simpler as systems grow, not more fragile. logging24 uses one forwarding path and one query model from single-host setups to multi-terabyte environments, so teams spend less time stitching tools together and more time operating systems.
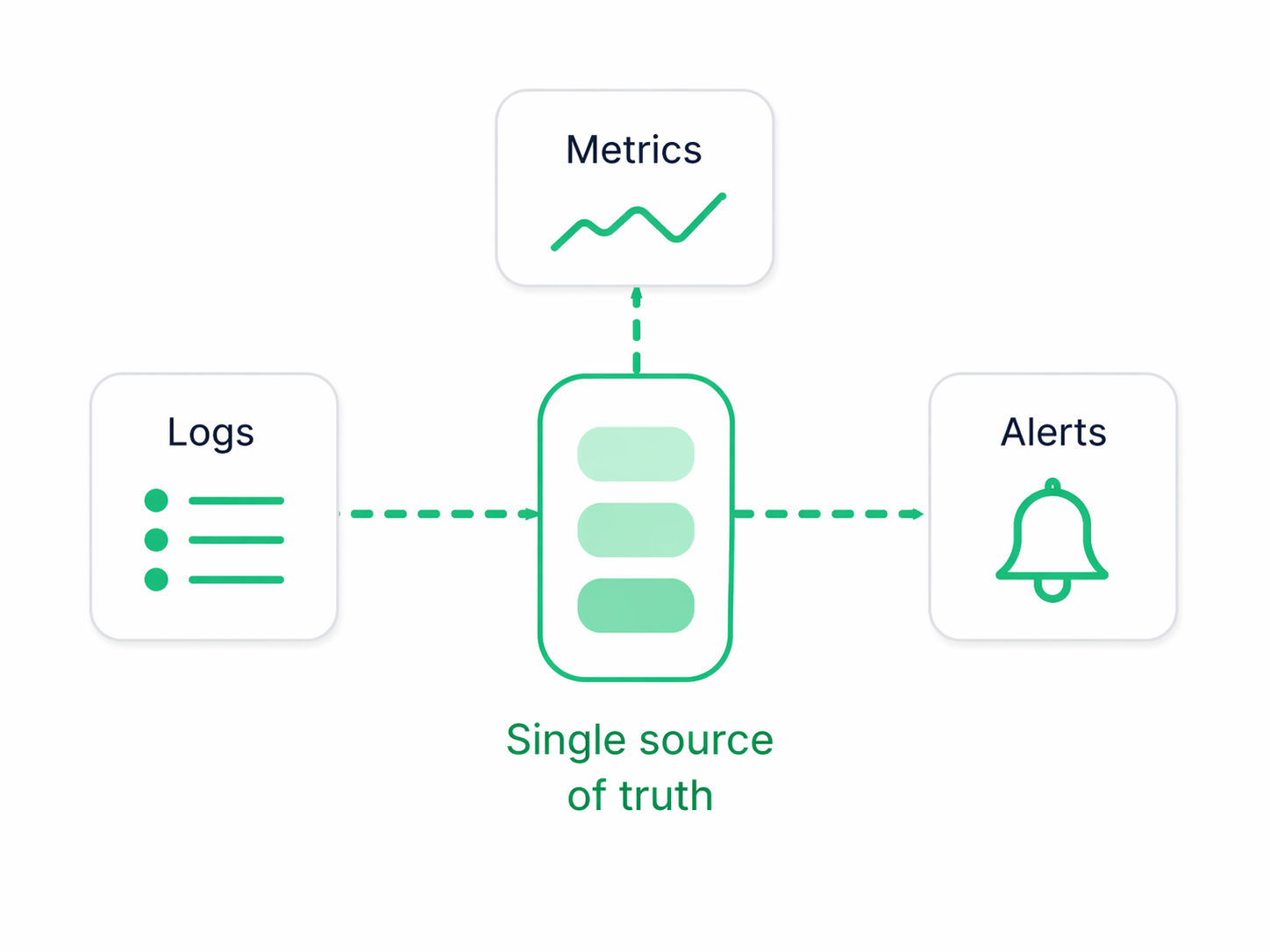
05. Unified Coverage
Use one dataset for logs, metrics, and alerts
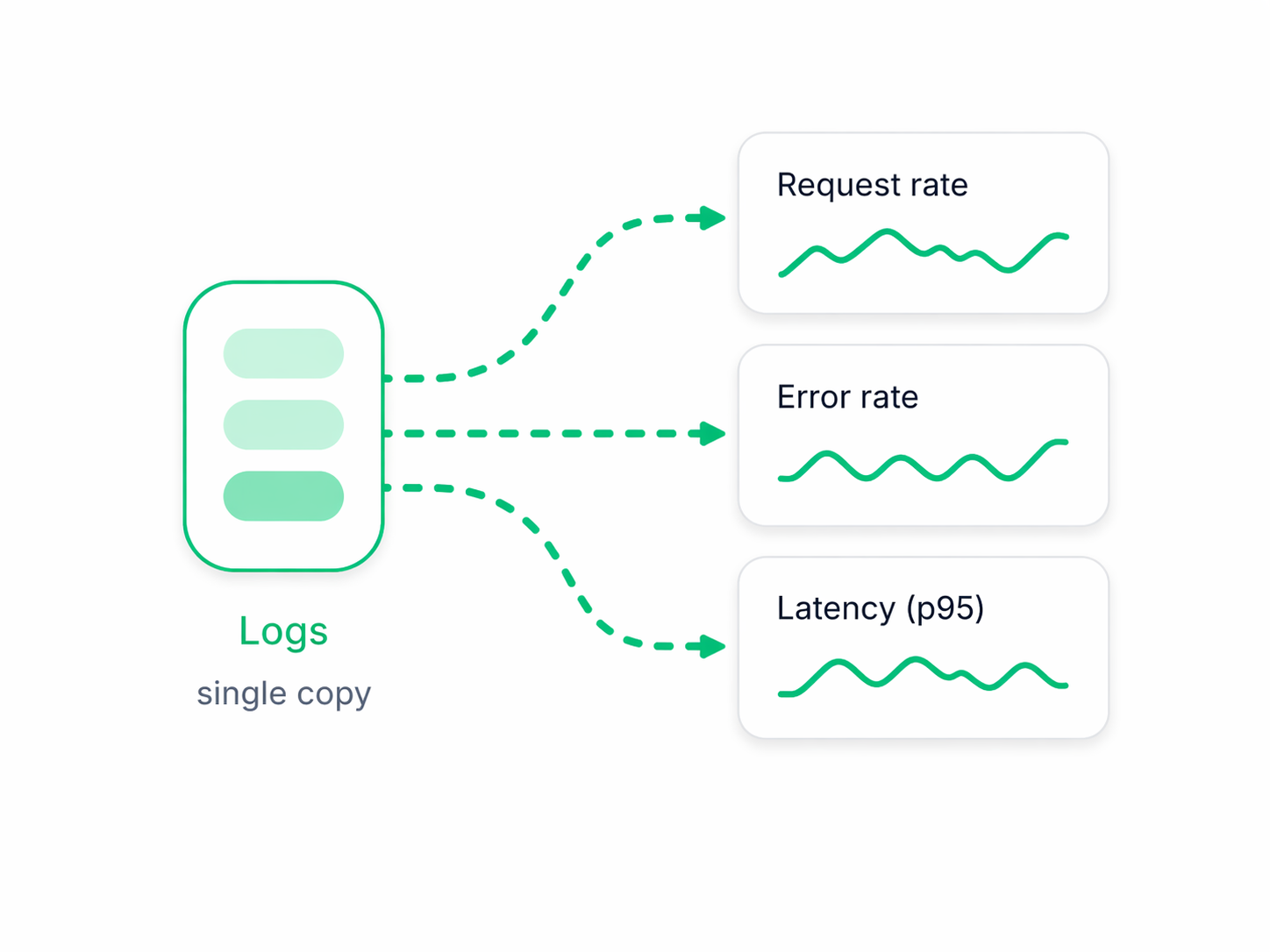
The observability benefit is not “more telemetry types.” It is having one place where troubleshooting, monitoring, and alerting reinforce each other. logging24 uses retained log events as the shared source so teams can move between investigation and monitoring without switching mental models or data stores. In practice, that means the traditional signals still matter, but they are powered from the same underlying data: logs remain the raw evidence, metrics are derived when needed, and trace-like correlation can be pursued directly from the recorded events.
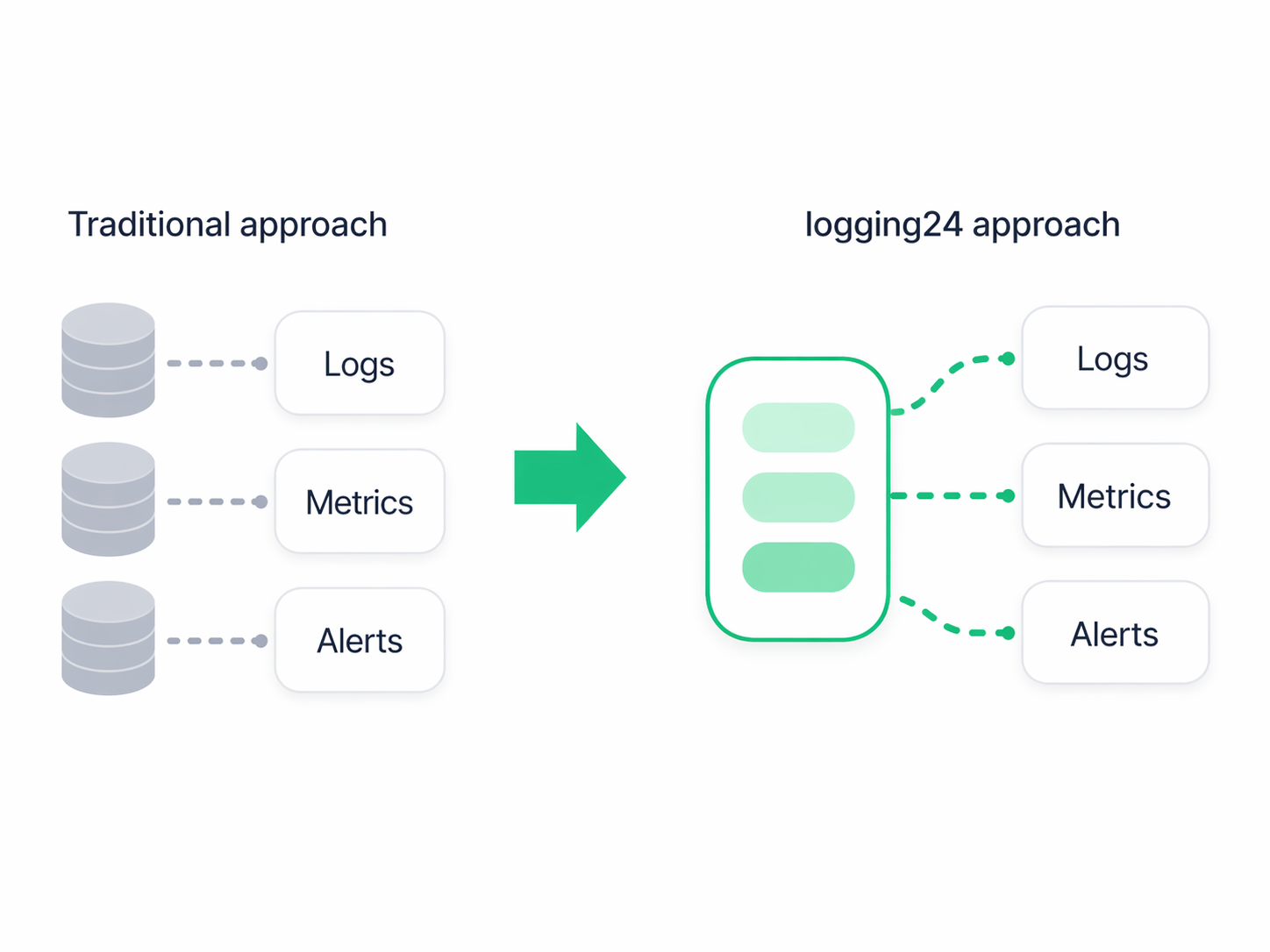
06. Cost and Control
Keep full detail without index-heavy pricing
A useful observability platform has to remain economically viable at retention and throughput levels real teams need. logging24 keeps one copy of the data, avoids indexing overhead, and offers predictable pricing so teams can retain detail without treating observability as a luxury.